ETL Monitoring and Observability Platform for a Multi-Tenant Data Provider
Enterprise observability for hundreds of warehouse jobs: dependency-aware alerting, deduplication, root-cause analysis, and AI-assisted remediation with safe automation.
Client
B2B data platform provider (multi-tenant analytics and warehouse product)
Location
North America
Platform
Cloud-native microservices (.NET APIs and workers, Next.js admin UI, Azure Container Apps)
Engagement Model
Dedicated Team
Team Size
7 specialists
Duration
14 months
Industries
Technologies
About The Customer
The Customer is a B2B data company that packages warehouse and analytics capabilities for many downstream clients. Their product sits on top of a large surface area: scheduled ETL and ELT data pipeline integrations, API-driven integrations, and mixed database estates. A meaningful share of workloads touches regulated or sensitive categories, so operational discipline, auditability, and tenant isolation were non-negotiable from day one.
Key Highlights
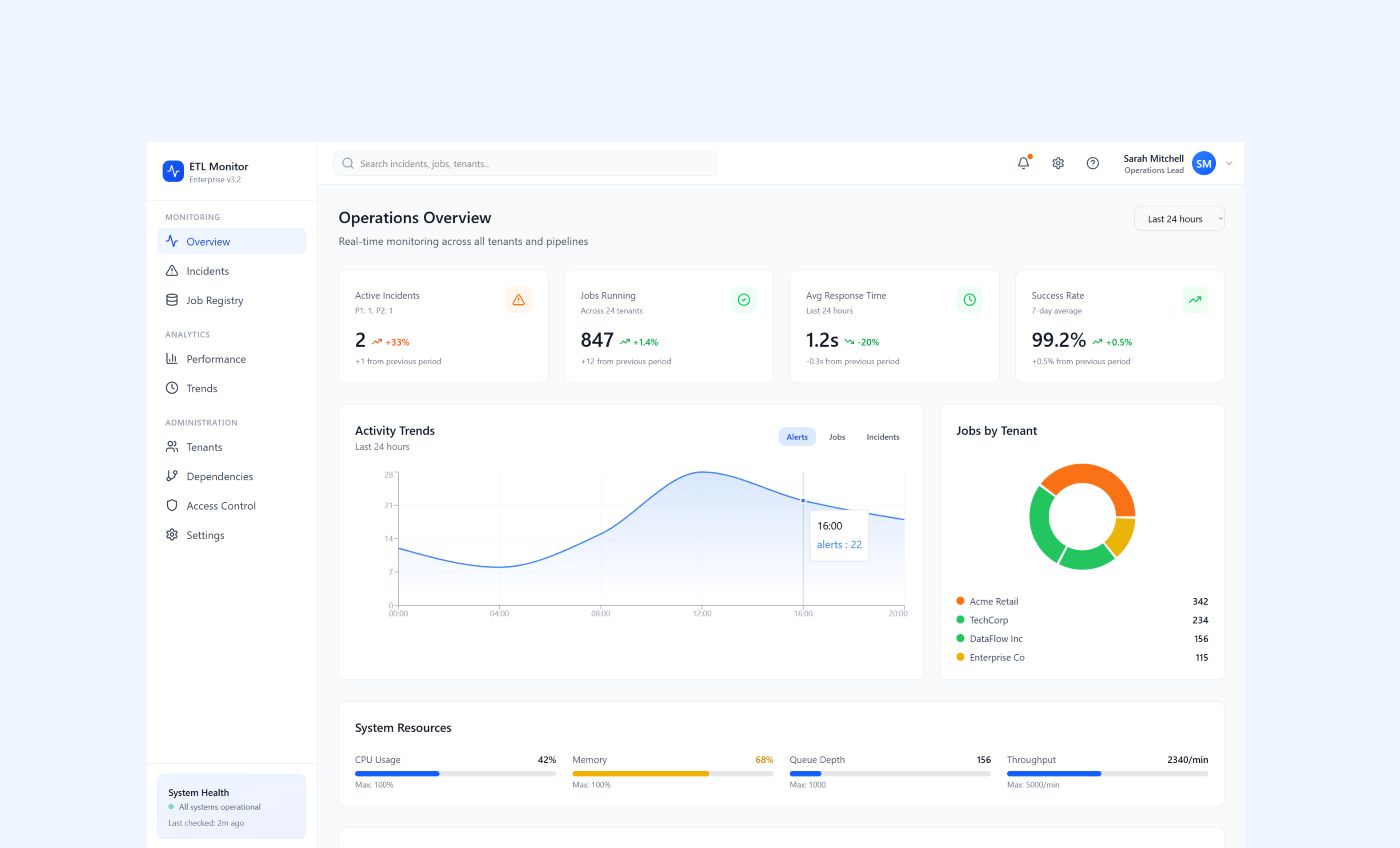
- Unified ingestion for health checks, job lifecycle signals, and API contract probes into one event model
- Time-windowed alert deduplication and incident aggregation to cut notification noise
- Dependency graph across jobs and systems to explain blast radius and group correlated failures
- Root-cause analysis and severity classification wired into Slack with calm, deduped notifications
- AI-assisted solution suggestions and optional GitHub pull requests for well-scoped, reviewed fixes - not silent production changes
- Admin experience for tenants, job registry, dependencies, and routing rules to speed up onboarding of new clients
The Challenge
The operations team was underwater. Every missed SLA or late batch produced another page - a classic ETL failure pattern - often duplicated across channels when the same upstream failure tripped dozens of dependent jobs. Engineers spent the first thirty minutes of every incident asking the same questions: what actually broke first, which tenants were impacted, and which alerts were symptoms versus cause.
Scaling the business made this worse. Each new tenant historically meant cloning brittle monitoring configuration, re-wiring dashboards, and hoping naming conventions matched reality. The Customer needed a single platform that could represent jobs and dependencies truthfully, enforce multi-tenant boundaries, and support both immediate response (late runs, missed windows, failed steps) and proactive signals (uptime, synthetic API checks, log-derived anomalies) - without drowning the team in noise.
Pain Points
- High alert volume with weak correlation across pipelines and warehouses
- Silent failures in downstream transforms going undetected until SLA breach
- Slow mean time to resolution when failures cascaded through dependency chains
- Inconsistent visibility across SQL Server and PostgreSQL schedulers, ETL tasks, scripts, and external APIs
- Heavy manual effort to onboard new clients into monitoring dashboard configuration and ownership rules
- Data quality degradation hard to trace across ETL process boundaries
- Pressure to automate remediation without bypassing change control or audit expectations
Challenges We Addressed
- Multi-tenancy: Every table and API path was designed with
tenant_idfirst, aligned with registry and routing so isolation mistakes did not leak events across customers or corrupt data loads between tenants. - Event scale and bursts: Ingestion spikes during batch windows had to be absorbed without dropping signals or overloading the primary database.
- Heterogeneous sources: Monitors in databases, HTTP health checks, and ETL process wrappers had to normalize into one schema the graph and classifiers could reason about.
- Safe automation: Auto-remediation and AI-generated fixes were constrained to pull requests, approvals, and audit logs - not blind production mutation.
Project Team Composition
- 2 Senior .NET engineers (collector and admin APIs, orchestrator worker, integrations)
- 1 Frontend engineer (Next.js admin UI, tenant and job management)
- 1 Data / platform engineer (Postgres model, Timescale-style metrics patterns, graph modeling)
- 1 DevOps engineer (Terraform, Azure Container Apps, CI/CD, observability baselines)
- 1 ML / automation engineer (RCA enrichment, solution generation, GitHub Actions wiring)
- 1 Project manager / business analyst (prioritization, stakeholder alignment, compliance touchpoints)
Our Solution
Softellar delivered a two-plane architecture: the data plane owns ingestion, durable processing, deduplication, graph and RCA computation, and outbound notifications. The control plane provides the admin UI and configuration APIs for tenants, jobs, dependencies, severity rules, and access - so operations and customer success could evolve the system without redeploying collectors.

Data plane: ingest, orchestrate, decide
External systems and agents post normalized events to a lightweight .NET collector API (health-style payloads with tenant_id, job_id, status, and structured details). The collector persists an append-only event record - tracking how many rows were processed, ETL run duration, and outcome codes - to PostgreSQL for traceability, then publishes to RabbitMQ so spikes never block the HTTP path.
A worker service backed by Temporal consumes the queue, executes activities with retries, and coordinates longer-running steps. Before opening a new incident, the worker checks Valkey (Redis-compatible) with TTL-based keys for deduplication - collapsing repeated failures into one actionable thread. Job state, key metrics, and graph-friendly projections remain in PostgreSQL, which also backs the registry of jobs, schedules, and dependencies.
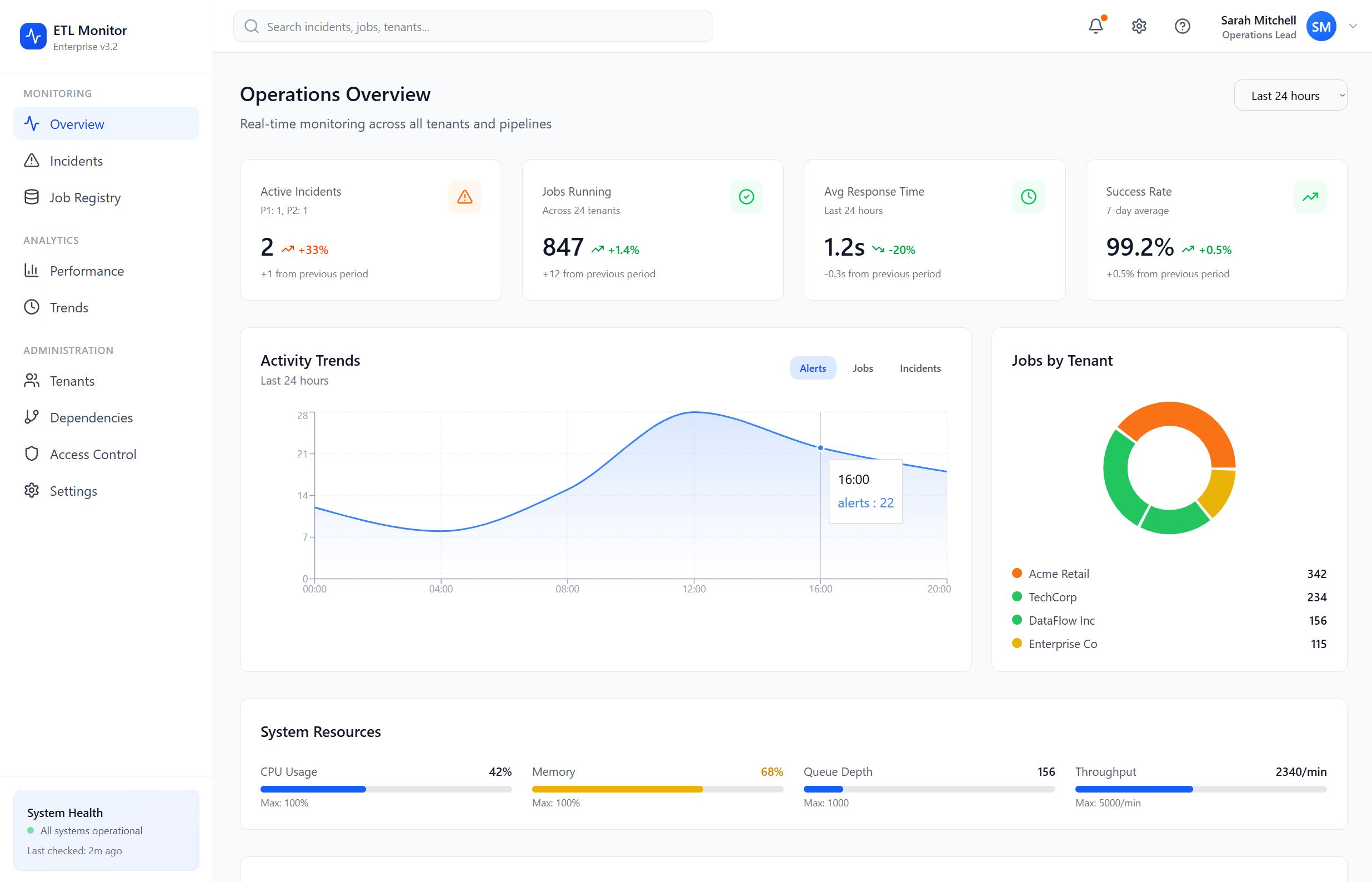
Control plane: admin UI and policy
The operations and business users on customer-facing teams use a React stack implemented with Next.js and TypeScript to list tenants, register jobs, edit dependency edges, tune severity and routing, review reports, and review audit history. A separate admin API enforces RBAC and keeps configuration changes explicit and versioned.
Dependency graph, RCA, and incident shaping
A dependency graph engine maps upstream and downstream relationships so a single root failure surfaces as one primary incident with linked affected jobs, instead of dozens of unrelated pages. Root-cause analysis combines structural signals from the graph with Temporal ordering of ETL pipeline events and log excerpts where available. A severity classifier scores customer impact and breach of SLO classes before Slack delivery.
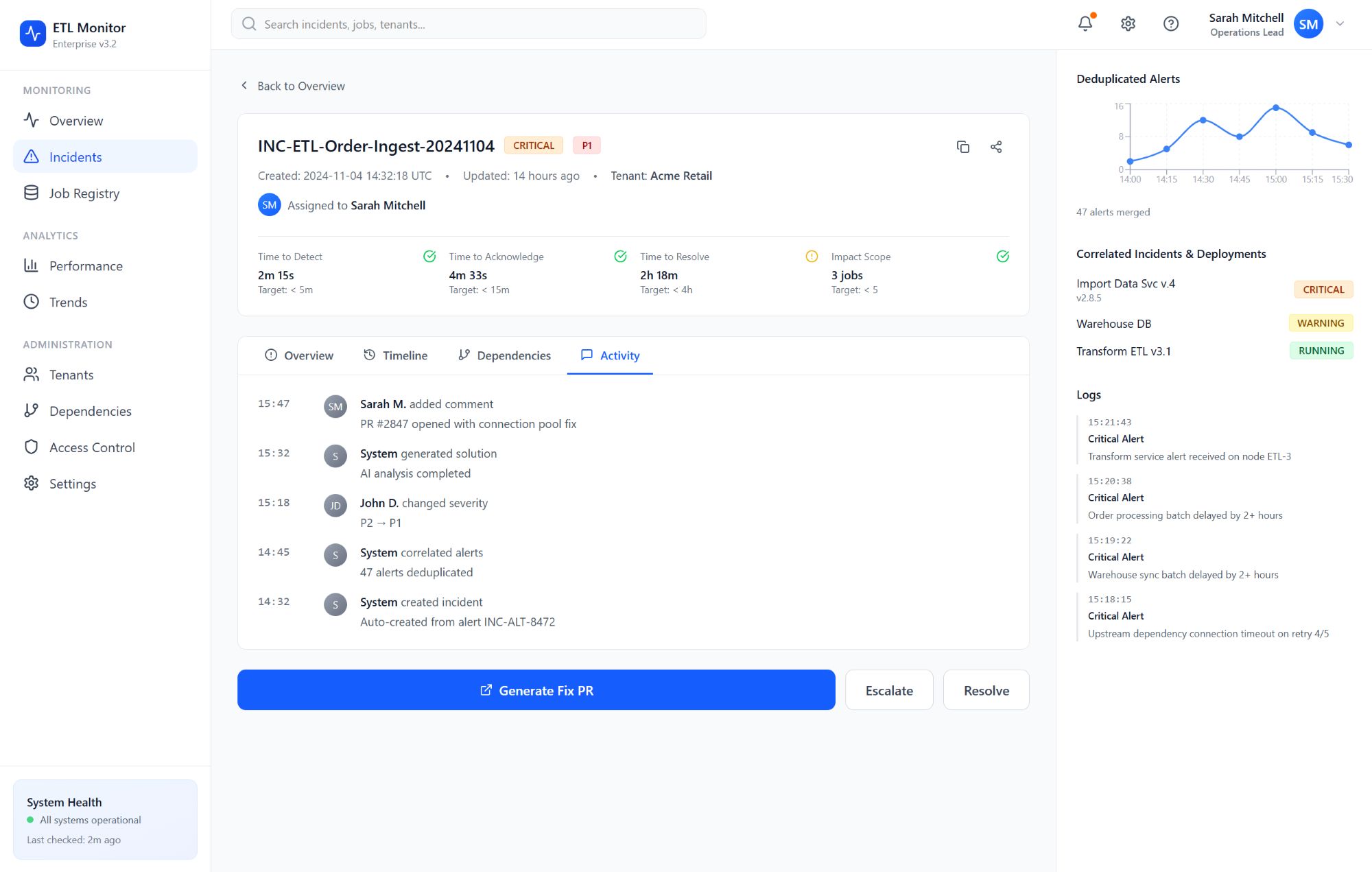
AI-assisted solutions, .NET integration, and pull requests
For suitable classes of defects - configuration drift, known flaky transforms, missing retries - the solution generator proposes concrete changes. Those proposals materialize as GitHub Actions-driven branches and pull requests, preserving code review and deployment pipelines. Human approval stays in the loop; the platform accelerates drafting and standardizes fix patterns rather than mutating production directly.
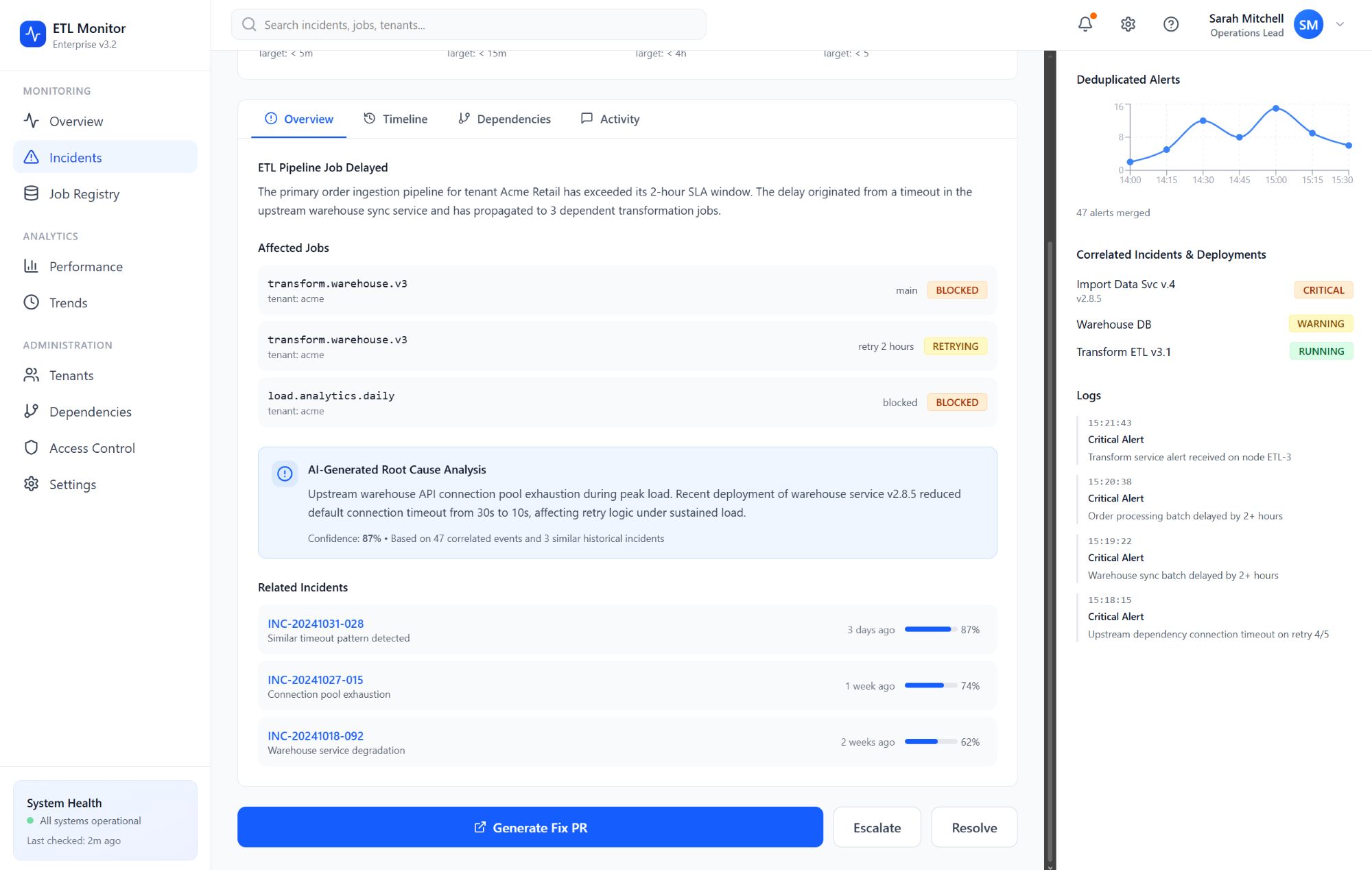
How AI is wired into the .NET stack
Inference runs out-of-process from interactive users: Temporal activities and background workers in .NET call a small AI gateway service (also .NET) using HttpClient with strict timeouts, retry budgets, and circuit breakers. The gateway's only job is to serialize a versioned analysis contract (JSON schema) into model prompts and parse structured responses back into domain objects: ranked root-cause hypotheses, short operator narratives, and optional patch hints that reference internal rule IDs rather than raw repository trees.
Orchestration stays deterministic: the workflow decides when to call the model, what contract version to use, and whether to skip AI entirely on hot paths. Model latency never blocks ingestion or deduplication; failed or slow calls degrade to heuristic RCA and still open incidents with a clear "AI unavailable" flag in audit metadata.
Security: no public AI and no sharing of proprietary code
The Customer barred sending intellectual property or full source to consumer-grade or multi-tenant public endpoints. Production traffic targets a private, customer-controlled deployment (Azure OpenAI in the same cloud tenant, private endpoints, and network rules that deny egress to unapproved hosts). Prompt construction is allow-listed: only normalized incident fields, dependency subgraph slices, scrubbed error codes, and short log fragments that already passed redaction pipelines are eligible fields - never entire files, solution folders, or connection strings.
- Policy enforcement in code: the gateway rejects payloads that exceed field length, contain path-like tokens, or match regexes for secrets before a request leaves the VPC.
- PR content: suggested fixes are expressed as diffs against approved templates or generated through internal static analysis plus model-generated descriptions; reviewers still see normal Git diffs in GitHub, not opaque remote edits.
- Telemetry: optional prompt/output logging is off by default for production; where enabled, retention and encryption match the Customer's data-classification rules.
API, uptime, and ETL lifecycle coverage
Beyond batch status, the same pipeline ingests synthetic API checks (request/response validation, latency thresholds), real time uptime probes, and data quality assertions on row counts. ETL jobs report started, completed, late, and missed outcomes - including rows loaded per ETL run - through thin client libraries and decorators in both Python and .NET environments so engineers could adopt ETL monitoring dashboard coverage with minimal boilerplate.
Why We Built It This Way
- Split collector and admin API: High-volume ingestion stays isolated from configuration workloads, limiting blast radius if either tier is stressed or misconfigured.
- Message broker: RabbitMQ smooths bursty batch windows and gives the team explicit back-pressure and operational tooling.
- Temporal: Durable workflows and retries replace ad-hoc cron glue for multi-step incident handling.
- Valkey for deduplication: Sub-millisecond checks with TTL fit the hot path better than relational contention for noise reduction keys.
- PostgreSQL as system of record: Events, registry, and projections share one auditable store the Customer could backup, replicate, and query for business intelligence and data warehouse analytics.
- Terraform and Azure Container Apps: Repeatable environments per stage, aligned with the Customer's cloud direction and autoscaling needs.
Our Approach
Delivery followed four deliberate phases:
- Discovery and architecture
Mapped job inventories, tenant model, and compliance constraints; chose the split data/control plane, broker, and orchestration stack; defined the canonical event schema and deduplication strategy. - MVP: trustworthy ingestion and noise reduction
Shipped collector API, PostgreSQL persistence, RabbitMQ fan-out, worker with Valkey deduplication, Slack notifier, and minimal registry APIs. - Graph, RCA, and admin experience
Introduced dependency modeling, incident aggregation keys (root cause, affected system family, severity band), Next.js admin UI for tenants and jobs, and Grafana-style read paths for historical analytics. - Intelligent remediation and hardening
Layered solution generation, GitHub PR automation, expanded synthetic checks, RBAC refinements, load testing, and runbooks for on-call.
Results and Impact
Outcomes are directional and depend on tenant mix, but the Customer reported materially faster triage, fewer duplicate escalations, and a repeatable playbook for onboarding new clients onto shared monitoring primitives.
Business outcomes
- Strong reduction in alert noise after deduplication and dependency-aware grouping
- Faster incident leadership because primary cause and blast radius were visible early
- Shorter time-to-first-dashboard for new tenants via registry-driven configuration
- Clearer audit story for who changed routing, severity, or automation policy
Technical outcomes
- Single event backbone for health checks, API probes, and ETL process lifecycle telemetry
- Data quality signals and rows-processed metrics surfaced per ETL job run
- Resilient processing under batch spikes using the broker and Temporal
- PR-based automation path that respects enterprise ETL tools and change control
- Infrastructure-as-code baselines for consistent Azure deployments across every environment
Tools and Technologies
.NET, C#, AI-assisted services, Next.js, TypeScript, PostgreSQL, Valkey, RabbitMQ, Temporal, Terraform, Azure Container Apps, Slack, GitHub Actions, ETL integrations across SQL Server and PostgreSQL estates - covering extract, transform, and load phases with unified ETL monitoring and data pipeline observability for organizations managing complex data warehouse estates.
For organizations facing similar complexity, our data architecture and cloud architecture practices align engineering, reliability, and scale-up goals end to end.
Strengthen Your Data Platform and Operations
From data architecture to reliable delivery - we help teams ship observable, scalable systems.
Related Case Studies

Fintech Cloud Case Study: AI Lending Platform on Azure for U.S. Private Credit
Industries:
Technologies:
Accounting Platform Modernization: Cloud-Native SaaS for a U.S. Payroll Software Provider
Industries:
Technologies:

Case Study: Microsoft Azure-Powered SaaS Invoice Recognition System
Industries:
Technologies: